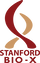As with most lab pages on current research projects, this one may be out of date, so feel free to reach out to us to find out the latest on what we're up to!
General Platforms for Designing Self-assembling Arrays, Biosensors, and Enzymes
De novo proteins make ideal scaffolds for a variety of downstream applications, owing to their structural simplicity and high stability. We recently de novo designed the (β/α)-8 barrel, or TIM barrel fold, as a 4x-repeat protein (see picture; PDB 5BVL). In nature, this is a very common fold for enzymes and binding small molecules. We also found that subunits of the de novo TIM barrel reassemble when expressed independently. These two properties - small molecule binding and catalysis, and subunit reassembly - have great potential for general solutions to problems in synthetic biology, medicine, and industry.
Heterodimers & Arrays - Heterodimer sets, which contain multiple orthogonally interacting pairs of proteins, have diverse applications in protein logic, synthetic biology, and molecular platforms and self-assembly. We are leveraging the unique properties of a de novo repeat TIM barrel protein which expresses solubly and stably in its constituent repeat subunits and reassembles in solution to design libraries of uniquely interacting protein pairs.
Biosensors & Enzymes - Biosensors are invaluable in monitoring cellular processes, detecting health/disease states, and in engineering cellular behavior. The current approach for biosensor development is to implement highly specific detectors for a target of interest, but this approach falls short in developing parallel sensors for a wide array of molecular markers known to be associated with health or disease state, and can be very difficult and expensive. Here, the TIM barrel scaffold presents a solution. We are working on using both the ligand-binding capacity of the TIM barrel as well as its self-reassembling properties to develop generalized chemically inducible dimers. In such a system, two half barrels with variable loops that can bind a target ligand dimerize into the full TIM barrel only in the presence of the ligand. This allows genetically encoded coupling of ligand presence to any dimerization-based readout, which can range from from fluorescent to enzymatic to transcription-inducing readouts. In a problem similar to designing ligand binding, the ability to design enzymes for any substrate or reaction would be tremendous for research and industry applications. However, enzyme design currently requires significant computational and experimental effort to achieve a single catalyst, which is hard to generalize to new ones. We are leveraging the structural compartmentalization of the TIM barrel to separately design catalytic motifs and ligand binding, which can then be reassembled in a modular fashion to generate catalysts for many substrates much more quickly.
De novo proteins make ideal scaffolds for a variety of downstream applications, owing to their structural simplicity and high stability. We recently de novo designed the (β/α)-8 barrel, or TIM barrel fold, as a 4x-repeat protein (see picture; PDB 5BVL). In nature, this is a very common fold for enzymes and binding small molecules. We also found that subunits of the de novo TIM barrel reassemble when expressed independently. These two properties - small molecule binding and catalysis, and subunit reassembly - have great potential for general solutions to problems in synthetic biology, medicine, and industry.
Heterodimers & Arrays - Heterodimer sets, which contain multiple orthogonally interacting pairs of proteins, have diverse applications in protein logic, synthetic biology, and molecular platforms and self-assembly. We are leveraging the unique properties of a de novo repeat TIM barrel protein which expresses solubly and stably in its constituent repeat subunits and reassembles in solution to design libraries of uniquely interacting protein pairs.
Biosensors & Enzymes - Biosensors are invaluable in monitoring cellular processes, detecting health/disease states, and in engineering cellular behavior. The current approach for biosensor development is to implement highly specific detectors for a target of interest, but this approach falls short in developing parallel sensors for a wide array of molecular markers known to be associated with health or disease state, and can be very difficult and expensive. Here, the TIM barrel scaffold presents a solution. We are working on using both the ligand-binding capacity of the TIM barrel as well as its self-reassembling properties to develop generalized chemically inducible dimers. In such a system, two half barrels with variable loops that can bind a target ligand dimerize into the full TIM barrel only in the presence of the ligand. This allows genetically encoded coupling of ligand presence to any dimerization-based readout, which can range from from fluorescent to enzymatic to transcription-inducing readouts. In a problem similar to designing ligand binding, the ability to design enzymes for any substrate or reaction would be tremendous for research and industry applications. However, enzyme design currently requires significant computational and experimental effort to achieve a single catalyst, which is hard to generalize to new ones. We are leveraging the structural compartmentalization of the TIM barrel to separately design catalytic motifs and ligand binding, which can then be reassembled in a modular fashion to generate catalysts for many substrates much more quickly.
Deep Learning for Protein Design
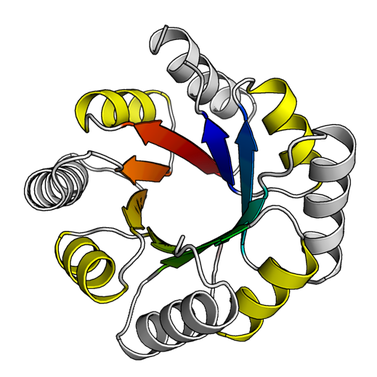
Applications of deep neural networks to chemistry and protein science have been important in modeling and predicting protein-protein and protein-small molecule binding interactions, predicting protein structure from sequence, and designing novel and functional protein sequences.
In our group, we build new machine learning tools to advance computational protein design and complement existing methods such as Rosetta. Some of our work involves building generative models of specific protein fold classes, such as immunoglobulins, which allows us to optimize and design protein structures for arbitrary functions. More generally, we are also working to encapsulate the universe of protein structures in generative models, by learning the underlying distribution of protein folding. These models would be able not only to assign class probabilities to structural motifs, but also produce protein folds and motifs de novo by sampling from the learned distribution. At the other end of the pipeline, we are also developing entirely knowledge-based methods to perform sequence design and rotamer packing in order to create novel sequences for de novo backbones. Together these two tasks constitute the "inverse folding" problem, which seeks to uncover the protein sequence space that is unexplored by nature.
Applications of deep neural networks to chemistry and protein science have been important in modeling and predicting protein-protein and protein-small molecule binding interactions, predicting protein structure from sequence, and designing novel and functional protein sequences.
In our group, we build new machine learning tools to advance computational protein design and complement existing methods such as Rosetta. Some of our work involves building generative models of specific protein fold classes, such as immunoglobulins, which allows us to optimize and design protein structures for arbitrary functions. More generally, we are also working to encapsulate the universe of protein structures in generative models, by learning the underlying distribution of protein folding. These models would be able not only to assign class probabilities to structural motifs, but also produce protein folds and motifs de novo by sampling from the learned distribution. At the other end of the pipeline, we are also developing entirely knowledge-based methods to perform sequence design and rotamer packing in order to create novel sequences for de novo backbones. Together these two tasks constitute the "inverse folding" problem, which seeks to uncover the protein sequence space that is unexplored by nature.
Superantigen-Inspired Cancer Immunotherapy
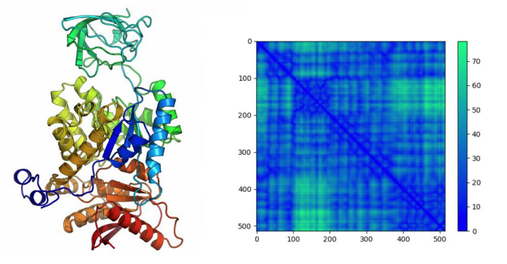
Controlled assembly of superantigens
Locally activating T-cells at the cancer site would serve as a powerful cancer immunotherapeutic; however, the cost of ex-vivo CAR T therapies and the challenges of reawakening effector immune cells in the tumor microenvironment have impeded development of effective cancer localized T cell activation. Superantigens are bacterial and viral proteins with immune stimulatory potential, capable of non-specifically activating large subsets of T cells. The application of the Rosetta software suite for macromolecular modeling has created new opportunities for protein design of these superantigens. We investigate the generation of self-assembling tumor-targeting superantigens, capable of inducing immune response only upon assembly at the site of interest.
Targeting MHC-presented tumor antigens
The previously described design for controlled assembly can be combined with a broad number of possible targeting components, Monoclonal antibodies have dominated immunotherapy because of their ability to target antigens in vivo at high affinity. However, these antibodies are limited to a narrow number of surface-expressed cancer targets. A broader class of surface antigens are antigenic peptides presented by MHC complexes, however it remains challenging to generate antibodies to bind specifically with those peptides. We are designing peptide specific pMHC binders inspired by superantigen structures, aimed at developing a pMHC barcode reading platform that is broadly applicable.
Controlled assembly of superantigens
Locally activating T-cells at the cancer site would serve as a powerful cancer immunotherapeutic; however, the cost of ex-vivo CAR T therapies and the challenges of reawakening effector immune cells in the tumor microenvironment have impeded development of effective cancer localized T cell activation. Superantigens are bacterial and viral proteins with immune stimulatory potential, capable of non-specifically activating large subsets of T cells. The application of the Rosetta software suite for macromolecular modeling has created new opportunities for protein design of these superantigens. We investigate the generation of self-assembling tumor-targeting superantigens, capable of inducing immune response only upon assembly at the site of interest.
Targeting MHC-presented tumor antigens
The previously described design for controlled assembly can be combined with a broad number of possible targeting components, Monoclonal antibodies have dominated immunotherapy because of their ability to target antigens in vivo at high affinity. However, these antibodies are limited to a narrow number of surface-expressed cancer targets. A broader class of surface antigens are antigenic peptides presented by MHC complexes, however it remains challenging to generate antibodies to bind specifically with those peptides. We are designing peptide specific pMHC binders inspired by superantigen structures, aimed at developing a pMHC barcode reading platform that is broadly applicable.
Building a Fuel-less, Light-Powered Molecular Motor
In the AsLOV2 protein domain, blue light oxidizes a flavin cofactor and causes the formation of a covalent bond between flavin and a cysteine residue on the main protein chain. The formation of this bond induces local conformational changes in AsLOV2 that are propagated through the protein, leading to the dislodging and unfolding of a C-terminal alpha helix. This change is dependable and reversible, and this system has been used to engineer many optogenetic systems for light-mediated control of different biological processes.
Flavin oxidation can be seen as a force generating event that acts upon the protein's conformational ensemble and shifts it to a new minimum. We seek to replace the need for ATP hydrolysis for energy production in molecular motors such as myosin VI by leveraging the force generated by a light-driven LOV2 domain. Such a project involves significant characterization and engineering of both the AsLOV2 domain and the myosin VI motor protein.
In the AsLOV2 protein domain, blue light oxidizes a flavin cofactor and causes the formation of a covalent bond between flavin and a cysteine residue on the main protein chain. The formation of this bond induces local conformational changes in AsLOV2 that are propagated through the protein, leading to the dislodging and unfolding of a C-terminal alpha helix. This change is dependable and reversible, and this system has been used to engineer many optogenetic systems for light-mediated control of different biological processes.
Flavin oxidation can be seen as a force generating event that acts upon the protein's conformational ensemble and shifts it to a new minimum. We seek to replace the need for ATP hydrolysis for energy production in molecular motors such as myosin VI by leveraging the force generated by a light-driven LOV2 domain. Such a project involves significant characterization and engineering of both the AsLOV2 domain and the myosin VI motor protein.